04 · 记忆——AI 怎么记住你
用日志层、提炼层和身份层解释 OpenClaw 记忆系统,区分上下文、长期记忆和身份文件。
——翔宇
要点速览
- LLM 本身是无状态的——每次对话从零开始,关掉就忘
- OpenClaw 用三层记忆架构解决这个问题:日志层 → 提炼层 → 身份层
- Context(上下文)不是长期记忆——它是桌上摊开的资料,关掉就没了
- Memory(记忆)才是柜子里的笔记本——持久保存在磁盘上
- 向量搜索让 Agent 按「意思」而不是「关键词」找回记忆
1. 一个好问题
你跟 Agent 说了 100 次「我喜欢简洁格式」。
关掉再打开,它还记得吗?
如果你用过 ChatGPT,你的直觉可能是「当然不记得」——因为每次新对话都是白纸一张。但如果你用的是 OpenClaw,答案是「看情况」。这个「看情况」背后,藏着整个记忆系统的设计逻辑。
🧠 底层逻辑
LLM(大语言模型)本身是无状态的——它没有硬盘,没有数据库,每次被调用时都像第一次见你。Claude、GPT、Gemini 全都一样。你在对话里说的任何话,关掉窗口就永远消失了。
这意味着:如果你想让 AI 「记住」你,不能靠 AI 自己——你必须在 AI 之外建一套记忆基础设施。
OpenClaw 就是这么做的。
2. 大多数人的直觉——为什么是错的
错误直觉
「Context(上下文)就是记忆吧?对话历史越长,AI 记得越多。」
这是最常见的误解。
Context 是 AI 当前能「看到」的所有内容——系统提示、对话历史、工具调用结果。它像你办公桌上摊开的资料。桌面大小有限(模型的上下文窗口,比如 200K token(词元,文本计量单位)),你不可能无限堆文件。
🎯 打个比方
Context 是桌上摊开的文件——关掉就收走了。Memory 是抽屉里的笔记本——什么时候打开都能翻。
更关键的是:当对话太长,OpenClaw 会触发 Compaction(压缩,旧对话摘要化)——把旧对话浓缩成一句摘要。如果你的「我喜欢简洁格式」只在聊天里说过,压缩后这句话很可能就丢了。
所以,Context 不是记忆。Context 是「正在看的」,Memory 是「存着的」。
📌 记住这点
Agent 需要历史信息时,从 Memory 搜索加载到 Context 里——就像从抽屉里抽一份文件放到桌上。记忆和上下文的流动方向是:Memory → Context,而不是反过来。
3. 如果你来设计:最笨的方案
假设你现在要给一个无状态的 AI 加上「记忆」能力。最笨的方案是什么?
方案一:全部塞进对话历史
每次开新对话时,把之前所有对话记录全部塞进去。
问题立刻出现:
- 第 1 天:对话历史 5,000 token,没问题
- 第 30 天:对话历史 150,000 token,勉强能塞进去
- 第 180 天:对话历史 900,000 token——超过任何模型的窗口限制
💬 说人话
你不可能每天早上到办公室,把入职以来所有的工作邮件全部打印出来堆在桌上。桌子会塌的。
方案二:记到文件里,每次全部加载
好一点。把重要信息记到文件里,每次对话时加载。
问题没消失,只是换了个地方:如果 Agent 每天记 500 字,半年后就是 90,000 字。全部加载到上下文?还是爆。
方案三:记到文件里,按需搜索加载
更聪明。记到文件里,只在需要的时候搜索相关内容加载。
但这又带来新问题:
- 怎么知道什么时候「需要」?
- 搜索准确率怎么保证?
- 重要的教训反复出现,每次都要搜吗?能不能变成「本能」? OpenClaw 的记忆系统,正是对方案三的逐步优化。
4. OpenClaw 的解法:三层记忆架构
💡 划重点
OpenClaw 官方提供两层记忆文件:
memory/YYYY-MM-DD.md(日志)+MEMORY.md(长期记忆)。下面的「三层架构」是翔宇在实际运营 10 Agent 组织时总结出来的最佳实践——把 SOUL.md 也视为记忆的最终归宿,形成完整的认知循环。
OpenClaw 不是用一种方式记忆,而是用三层——每一层解决不同的问题。
Layer 1: 日志层 memory/YYYY-MM-DD.md 每次任务完成后追加,原始记录
↓ 达到阈值时自动提炼
Layer 2: 提炼层 MEMORY.md 从日志筛选跨会话复用的信息
↓ 同一模式出现 ≥3 次
Layer 3: 身份层 SOUL.md / TOOLS.md 教训永久写入身份文件
🎯 打个比方
Layer 1 是你的工作日报——今天做了什么、遇到了什么问题。
Layer 2 是你的笔记本——从日报里提炼出值得记住的经验。
Layer 3 是你的性格和习惯——反复犯同一个错之后,你把它变成了本能反应。
4.1 为什么必须三层?
这不是过度设计。让我们用反事实推理来证明每一层都不可或缺。
如果只有 Layer 1(日志),没有 Layer 2 和 3?
Agent 每天写日志。半年后 180 个文件。每次启动加载全部?上下文直接爆炸。只加载最近几天?一个月前学到的教训就丢了。
💬 说人话
你有 180 本日记,但没有笔记本。每次做决定都要翻所有日记,根本翻不过来。
如果只有 Layer 1 和 Layer 3(日志 + 身份),没有 Layer 2?
日志层记录太多细节,身份层只放最核心的规则。中间没有缓冲——一个教训要么留在日志里(几天后被遗忘),要么直接写进身份文件(但还不确定它是否真的重要)。
💬 说人话
你要么翻日记,要么看性格手册,但没有笔记本。工作中的重要发现没地方暂存——直接写进性格手册太草率,留在日记里又会被埋没。
三层的优雅之处:
Layer 2 是关键的缓冲层——它让信息在「刚发现」和「变成本能」之间有一个观察期。只有反复出现 3 次以上的模式,才值得晋升到身份层。
🔑 关键点
三层记忆不是「数据库分表」这种技术优化,而是「认知过程的建模」——人类的记忆也是这样工作的:经历(日志)→ 总结(笔记)→ 习惯(本能)。
4.2 一个具体例子:跟着一条信息走完三层
假设你跟 Agent 说了一句:「以后部署都用 Docker,不用裸机部署了」。
第一天:这句话存在于 Context 中。memoryFlush(记忆刷写,压缩前抢救机制)触发时,Agent 把它写入 memory/2026-03-15.md:
## 部署偏好
用户决定:以后部署统一用 Docker,不再裸机部署。
原因:裸机部署环境差异太大,Docker 容器保证一致性。
/图片这条信息现在在 Layer 1(日志层)。
第三天:你又提了一次「用 Docker 不用裸机」。Agent 在 memory/2026-03-17.md 里又记了一次。Heartbeat(心跳,定期自动巡检)巡检时发现这个模式出现了 2 次,提炼到 MEMORY.md:
## 用户偏好
- 部署方式:Docker 容器化,禁止裸机部署(多次确认)
这条信息现在在 Layer 2(提炼层)。
第十天:你第三次提到 Docker。周复盘 Cron(定时任务)扫描发现这条规则出现 3 次以上,标记 [待晋升],并写入 SOUL.md 的决策框架部分:
## 决策框架
- 部署方式:永远用 Docker,不用裸机。无需再确认。
这条信息现在在 Layer 3(身份层)——它变成了 Agent 的「本能」。以后你说「帮我部署个服务」,Agent 会自动用 Docker,不需要你提醒。
🔑 关键点
整个过程是自动的——你不需要手动管理三层之间的流转。Agent 自己写日志,Heartbeat 自己提炼,周复盘自己晋升。你要做的只有一件事:把真正重要的规则直接写进 SOUL.md,不要等它慢慢晋升。
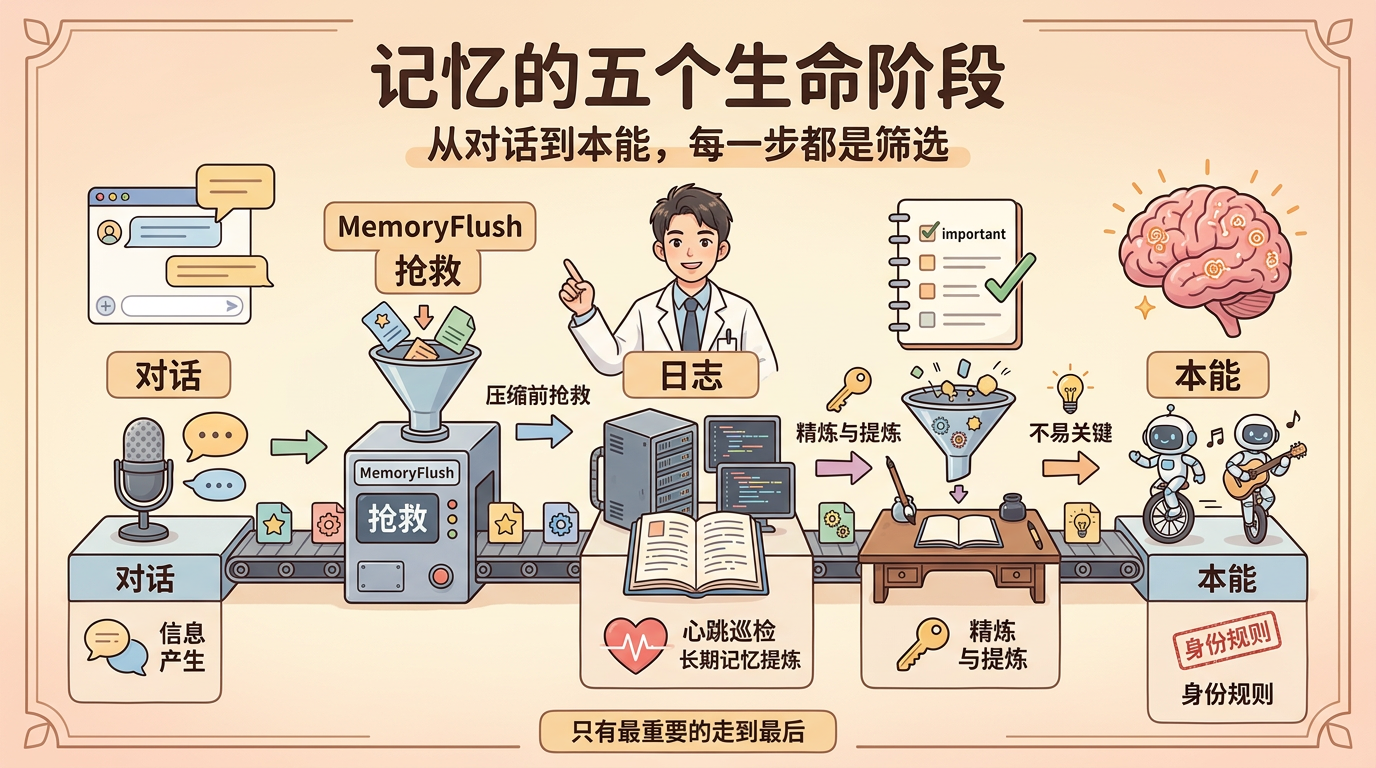
5. 记忆的五个生命阶段
一条信息从「刚刚发生」到「变成 Agent 的本能」,要经历五个阶段。
5.1 阶段一:对话中产生
你在聊天中说了一句:「以后回复用 Markdown 表格格式」。
这句话现在只存在于 Context(桌面)中。如果会话结束或压缩触发,它就消失了。
5.2 阶段二:memoryFlush 抢救
🧠 底层逻辑
当 Agent 的上下文快要触发压缩时,OpenClaw 会先运行一个静默轮次——提醒 Agent:「快要压缩了,赶紧把重要的东西记下来。」
这就是 memoryFlush——压缩前的「抢救机制」。Agent 会把值得记住的信息写入 memory/今天.md。
🎯 打个比方
考试快交卷了,老师提醒你「把重要答案再检查一遍」。Agent 在压缩前把关键信息存进文件。
默认触发条件:上下文的 token 估算值超过 contextWindow - reserveTokensFloor - softThresholdTokens 时触发。以 200K 窗口为例:200,000 - 20,000 - 4,000 = 176,000 token。也就是说,当上下文使用量接近窗口上限的 88% 时,memoryFlush 才会触发——这是一个「快要满了」的预警,而不是「刚开始聊」就触发。
📌 记住这点
softThresholdTokens: 4000不是「4000 token 就触发」的意思——它是一个间距参数,定义的是「距离压缩还有多远时开始抢救」。真正的触发点取决于模型的上下文窗口大小和 reserveTokensFloor 的设置。
5.3 阶段三:写入日志(Layer 1)
信息被写入 memory/YYYY-MM-DD.md——今天的日志文件。这个文件只追加、不修改。
会话结束时(/new、/reset、idle 超时、daily reset),session-memory hook 也会触发写入。
📌 记住这点
日志层是「仅追加」的——只写不改。这保证了完整的时间线记录,不会因为后来的理解变化而覆盖原始信息。
5.4 阶段四:提炼到 MEMORY.md(Layer 2)
Heartbeat(心跳巡检)每隔一段时间自动扫描最近 2-3 天的日志。如果发现同一模式重复出现 2 次以上,就提炼到 MEMORY.md。
例如,日志里出现了 3 次「用户要求回复用表格格式」,Heartbeat 就会在 MEMORY.md 里写一条:「用户偏好:回复使用 Markdown 表格格式」。
周反思 Cron(通常每周日运行)做更深入的扫描——看过去 7 天的日志,提炼规律性发现。
5.5 阶段五:晋升到身份层(Layer 3)
如果 MEMORY.md 里某条记录被标记为 [待晋升](同一模式出现 3 次以上),周复盘时会被永久写入 SOUL.md 或 TOOLS.md。
到了这一步,「用户偏好表格格式」不再是一条笔记,而是变成了 Agent 的「性格」——它不需要搜索就会自动遵守。
🎯 打个比方
你第一次被烫到手(日志),记了一笔「炉子很烫」(笔记),下次还是被烫了,再记一次,第三次之后你的手会自动缩回来(本能)。Layer 3 就是这个「本能」。
5.6 完整流转可视化
对话中产生
↓ memoryFlush(上下文 ≥4000 token 时自动触发)
memory/YYYY-MM-DD.md(Layer 1:日志层)
↓ Heartbeat 巡检(定期扫描 2-3 天日志)
MEMORY.md(Layer 2:提炼层)
↓ 同一模式 ≥3 次 → 标记 [待晋升]
SOUL.md / TOOLS.md(Layer 3:身份层)
⚡ 速记
五个阶段:对话 → 抢救 → 日志 → 笔记 → 本能。每一步都是筛选——只有真正重要的信息才能走到最后。
6. 启动恢复:Agent 早上到办公室
理解了三层架构,接下来的问题是:Agent 重启(或新会话开始)时,它怎么「回忆」?
答案是按固定顺序加载。
1. 读 SOUL.md → USER.md → TOOLS.md
(身份层最先——先确认「我是谁」)
2. 读 memory/今天.md + 昨天.md
(最近的日志——看昨天有没有没做完的事)
↳ 找 [进行中] 标记,恢复未完成任务
3. 读 MEMORY.md
(长期记忆——回忆重要决策和偏好)
🎯 打个比方
就像你早上到办公室:先看工牌确认自己是谁(SOUL),再翻昨天的便签看有没有没做完的事(daily log),最后翻笔记本回忆重要决策(MEMORY.md)。
💡 划重点
注意加载顺序——身份层(Layer 3)最先加载。这意味着写在 SOUL.md 里的规则,Agent 一定会看到。而写在日志里的信息,只有最近 1-2 天的才会被加载。这就是为什么重要规则必须「晋升」到 SOUL.md——否则几天后就不在默认加载范围了。
7. memoryFlush:压缩前的紧急抢救
memoryFlush 值得单独拿出来讲,因为它的设计非常巧妙。
7.1 问题场景
Agent 和你聊了 30 轮。上下文快满了。OpenClaw 准备触发 Compaction(压缩)——把旧对话浓缩成一句摘要。
但压缩意味着细节丢失。如果这 30 轮里你说过一些重要的事(比如「下次部署用 Docker 不用裸机」),压缩后就可能找不到了。
7.2 OpenClaw 的解法
在压缩之前,插入一个静默轮次:
🧠 底层逻辑
OpenClaw 不是直接压缩,而是先给 Agent 一个「临终关怀」的机会——让它把重要信息写入记忆文件,然后再压缩。Agent 看不到这个过程,用户也看不到,一切都在后台自动完成。
这就像搬家前先整理行李——不是把所有东西都扔掉,而是先把值钱的东西装箱(写入 Memory),再清空房间(压缩 Context)。
7.3 触发条件
📌 记住这点
memoryFlush 是默认开启的。如果你发现 Agent 「失忆」了,先别慌——它可能已经把重要信息存进了
memory/目录。用memory_search搜一下。
8. 向量记忆搜索:按「意思」找东西
记忆文件多了之后,怎么快速找到需要的信息?
传统方法是关键词搜索——搜「Docker」,找到所有包含「Docker」这个词的记忆。但如果你记的是「容器化部署」呢?关键词搜索就搜不到了。
OpenClaw 用向量搜索解决这个问题。
🎯 打个比方
关键词搜索像在图书馆里按书名查——你必须知道确切的书名。向量搜索像问图书管理员「我想找一本关于怎么在服务器上跑程序的书」——他能推荐你《Docker 实战》,即使你的描述里没有「Docker」这个词。
8.1 混合搜索:两全其美
OpenClaw 不是只用向量搜索,而是把向量搜索和关键词搜索组合起来:
默认权重:向量 70% + 关键词 30%。大部分场景不需要调整。
8.2 搜索工具
Agent 有两个内置工具来访问记忆:
memory_search:语义搜索,返回文件名 + 相关片段memory_get:按路径直接读取记忆文件
8.3 为什么搜不到:三个常见坑
错误直觉
「我刚记了一条信息,搜索应该马上能找到。」
不一定。
坑 1:向量索引还没更新
💡 划重点
刚写入的记忆,最长要等 1 小时才能被语义搜索命中。这不是 Bug——向量索引每 60 分钟重建一次。急着找?用精确关键词搜索(5 分钟更新)而不是语义搜索。
坑 2:记忆片段太短
少于 50 个字符的记忆可能不会被索引。写记忆时尽量完整——「用户偏好 Claude 模型,因为它回复更准确」比「Claude」更容易被检索到。
坑 3:相关度阈值
默认有 minScore 阈值,语义距离太远的结果会被过滤。如果搜不到,试试换不同的搜索词——用更具体的描述替代抽象的关键词。
8.4 Embedding 是怎么工作的
🔍 深入一步
你不需要理解这部分也能用好记忆搜索。但如果你好奇「按意思搜索」到底怎么实现的,继续读。
向量搜索的核心是 Embedding(向量嵌入,文本转数字)——把文字转换成一串数字(向量),语义相近的文字会被转换成距离相近的向量。
「我喜欢用 Docker 部署」 → [0.23, 0.67, 0.91, ...]
「容器化方案很好用」 → [0.21, 0.65, 0.89, ...] ← 距离很近!
「今天天气不错」 → [0.82, 0.14, 0.33, ...] ← 距离很远
搜索时,OpenClaw 把你的查询也转换成向量,然后在所有记忆向量中找距离最近的——这就是「语义匹配」。
Embedding 提供商自动选择:
🔍 深入一步
还支持 Ollama(本地/自托管)和自定义 OpenAI 兼容端点,但不在自动选择范围内,需要手动配置。
💬 说人话
如果你有 OpenAI API Key,向量搜索会自动启用。没有也行——关键词搜索照样能用,只是不能按「意思」搜。
8.5 记忆搜索的完整流程
当 Agent 需要查找历史信息时,搜索按这个流程走:
Agent 收到消息:"上次我们决定用什么方案部署?"
↓ Agent 判断需要搜索记忆
↓ 调用 memory_search 工具
↓
混合搜索引擎
├─ 向量搜索(70% 权重):把查询转成向量,找语义最近的记忆片段
└─ 关键词搜索(30% 权重):在记忆文件中找包含「部署」「方案」的片段
↓ 合并结果,按综合相关度排序
↓ 过滤掉低于 minScore 阈值的结果
↓
返回:memory/2026-03-15.md 第 12-15 行
内容:"用户决定以后部署统一用 Docker..."
↓
Agent 把这段记忆加载到当前 Context 中
↓
回复你:"上次你决定用 Docker 部署,不再用裸机。"
📌 记住这点
搜索结果会被加载到 Context(桌面)中——这意味着每次搜索都消耗上下文空间。Agent 不会把所有记忆都搜出来,而是只取最相关的几条。
9. RAG 知识库 vs 记忆系统:两个完全不同的东西
很多人把 RAG(检索增强生成)和 Memory(记忆)混为一谈。它们解决的是完全不同的问题。
🎯 打个比方
记忆是员工自己的笔记本——每天工作记下的经验。知识库是公司的资料室——你(老板)放进去的文档。前者跟着员工走,后者属于公司。
🔑 关键点
如果你想让 Agent 记住「用户偏好」,用 Memory。如果你想让 Agent 查阅「公司规范」,用知识库(extraPaths)。
9.1 一个真实场景对比
💬 说人话
简单判断法:谁写入的? Agent 自己记的 → 记忆。你放进去的 → 知识库。
9.2 知识库怎么配置
在 openclaw.json 中用 extraPaths 指定知识库目录:
Agent 会在需要时自动检索这些目录里的文件——你不需要手动告诉它去查。
🔍 深入一步
extraPaths 支持多个目录。你可以把不同类型的文档放在不同目录——代码规范、API 文档、内部 Wiki 各一个。Agent 搜索时会同时查所有目录。
10. 什么时候写 Memory
不是所有信息都值得记。写 Memory 的原则:
📌 记住这点
用户说「记住这个」时,Agent 应该立即写入磁盘,不犹豫。这是记忆系统最直接的触发方式。
10.1 记忆反模式:这些错误别犯
🧠 底层逻辑
记忆系统的核心原则是「少即是多」——Agent 不需要记住所有事情,只需要记住影响未来决策的信息。一条清晰的偏好规则(「用户只接受表格格式」)比十条模糊的日志记录更有价值。
10.2 记忆卫生:定期维护
Agent 的记忆需要人类定期审查——就像员工的笔记本需要主管偶尔翻翻看。
月度审查清单:
11. 设计权衡:为什么这么设计
设计权衡
🧠 底层逻辑
OpenClaw 选择 Markdown 文件而不是数据库,核心原因是「文件即真相」的设计哲学——你可以用任何文本编辑器打开记忆文件、手动修改、用 Git 版本控制。如果用数据库,这些都做不到。代价是搜索性能不如数据库,但混合搜索弥补了大部分差距。
一句话检验
如果你能用一句话回答以下问题,你就真正理解了 OpenClaw 的记忆系统:
- Context 和 Memory 的区别? → Context 是桌上的资料(临时),Memory 是抽屉里的笔记本(持久)
- 为什么要三层? → 日志太多会爆,身份层太严肃不能乱写,中间需要一个观察期
- memoryFlush 是什么? → 压缩前的紧急抢救——把重要信息从桌面存进抽屉
- 向量搜索的优势? → 按意思搜而不是按关键词搜——不用记住精确用词
CC 提示词
理解了原理,现在用 Claude Code 验证一下你的 Agent 记忆系统是否正常工作。
🚀 对 Claude Code 说 帮我检查 OpenClaw 的记忆系统健康状态: - 列出 /你的路径/.openclaw/workspace/memory/ 下的所有文件,统计文件数量和总大小
- 读取最近一天的记忆日志内容,告诉我 Agent 记了什么
- 检查 MEMORY.md 是否存在,如果存在显示内容并分析记忆质量
- 检查 SOUL.md 里是否有从记忆晋升上来的规则(看是否有具体的行为决策规则,而不只是泛泛的身份描述)
- 综合评估:记忆系统是否在正常流转?有没有 Layer 1 满但 Layer 2 空的情况?
🚀 对 Claude Code 说 帮我测试 OpenClaw 的记忆搜索功能: - 在 OpenClaw 聊天中让 Agent 记住一条测试信息:「测试记忆:我喜欢用表格格式」
- 等待 5 分钟后,搜索关键词「表格」看是否能找到
- 再用语义搜索「回复的格式偏好」看是否能匹配到
- 报告两种搜索的结果差异
延伸阅读
理解了记忆的设计原理后,以下翔宇版教程有更多操作细节:
- 翔宇版 04《核心概念深度解析》— Memory 全节:记忆文件布局、写入时机、搜索命令
- 翔宇版 11《系统参数深度解读》— memoryFlush、memorySearch 的完整参数手册
- 翔宇版 08《自动化与集成》— Heartbeat 心跳如何自动提炼记忆